Comprendre Internet et son fonctionnement

Dans cet article, j’introduis les notions et concepts nécessaires à la compréhension d’Internet et aux réseaux de données en général.
Cet article est basé sur le chapitre de mon ouvrage intitulé “Technologies et protocoles Internet” publié dans la collection Références sciences des éditions Ellipses.

Cet article concentre en grande partie sur les notes de cours de l’unité d’enseignement LU3IN033 que Promethee Spathis enseigne à Sorbonne Université et que vous pouvez visionner sur YouTube.
Les données, d’où viennent-elles et pourquoi les transporter ?
Les données font référence aux bits que génèrent les applications exécutées à l’initiative des utilisateurs sur leur ordinateur. Des exemples d’applications sont les navigateurs Web, les clients mail ou un client BitTorrent. Toutes ces applications sont des programmes qui communiquent avec un programme homologue, exécuté sur une machine distante.

Modèle client-serveur
Originellement, ces deux programmes étaient conçus de manière asymétrique : le programme distant diffère de celui exécuté sur l’ordinateur des utilisateurs. En tant qu’utilisateurs, nous nous connectons à un réseau de données en vue de recevoir une page web, des images, un email ou une vidéo. Ces objets sont hébergés sur des machines appelées serveurs. Nous sommes les clients de ces machines qui, du fait de répondre à nos requêtes, sont appelées serveurs.
Les serveurs offrent des capacités de stockage qui leur permettent d’héberger des contenus accessibles à tous. Les serveurs disposent également de capacités de traitement qui leur permettent de traiter les requêtes de leurs clients.
Modèle pair-à-pair
Récemment, on a vu l’avènement d’un nouveau type d’applications résultant de l’exécution de programmes identiques. On parle d’applications pair-à-pair où une même machine peut agir aussi bien en tant que client que serveur.
Interopérabilité
Applications client-serveur ou pair-à-pair sont mises à disposition au téléchargement par leurs développeurs. Les utilisateurs sont libres d’installer ces applications sur leur ordinateur. Il n’y a pas, à proprement parler, de réel contrôle concernant les applications qu’un utilisateur peut installer sur son ordinateur.
Qu’ils s’agissent des constructeurs de matériel informatique ou des concepteurs de systèmes d’exploitation qui équipent nos ordinateurs à leur achat, tous œuvrent dans le but de concevoir des équipements ouverts et interopérables qui rendent leurs produits attractifs du fait de leur versatilité. C’est ce qui a fait le succès de l’Internet.
L’utilisation de certains logiciels peut être restreinte. Un fournisseur d’accès Internet (FAI) peut éventuellement être soumis aux lois nationales contre le piratage informatique ou la violation des droits d’auteur par exemple. Pour autant, les FAI ne sont pas toujours en mesure de filtrer avec succès les trafics dérogeant à ces lois.
Comment les données sont-elles ‘emballées’ en vue de leur transport ?
A la manière des produits ou denrées transportés par un transporteur tel que Colissimo ou UPS, les données ont besoin d’être emballées.
Fragmentation
Dans un réseau de données, les données sont fragmentées : une longue série de bits de données appartenant à un même fichier est répartie dans plusieurs colis appelés messages.
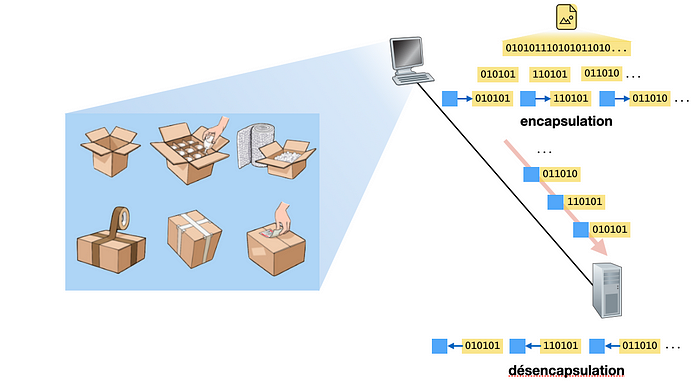
Encapsulation et désencapsulation
L’équivalent des cartons d’emballage sont des bits supplémentaires ajoutés généralement en tête des bits de données appelés de ce fait, entête. A la manière des dimensions ou du poids d’un colis, la longueur des messages exprimée en nombre de bits est soumise à des restrictions qui imposent une longueur minimale et maximale. L’ajout d’un entête est appelé encapsulation et le retrait de l’entête désencapsulation.
Entête et charge utile
Dans un réseau de données, un colis est donc un message constitué d’un entête et des bits de données. Les bits de données forment le corps du message que l’on appelle aussi charge utile du message. Les messages ayant une longueur maximale, plusieurs messages sont nécessaires pour transmettre un même objet telle qu’une image.
Dans l’entête d’un message, on retrouve des bits appelés informations de contrôle telles que l’adresse du destinataire et celle de l’expéditeur. A la manière du papier-bulle utilisé pour éviter la casse des produits fragiles, l’entête peut également contenir des bits appelés somme de contrôle permettant de détecter les bits reçus en erreur. Une fois détectées, on peut réparer les erreurs en retransmettant les messages erronés.
Les bits correspondant aux adresses ou la somme de contrôle sont des exemples de champs. Un entête est une succession de champs dont la longueur est variable ou fixe. La structure d’un entête aussi appelé format d’un entête fait référence aux champs qui composent cet entête. Pour chaque champ est précisé le nom, la longueur en bits, et sa signification selon la valeur qu’il contient. La valeur d’un champ peut être fournie sous la forme d’un code binaire (la valeur 0x06 fait référence au protocole TCP) ou du code ASCII de la valeur en question (la valeur 0x474554 indique la méthode GET).
Transporter les données avec des garanties
L’entête d’un message étant ajouté dans un but précis, plusieurs entêtes sont nécessaires afin d’assurer les nombreuses propriétés attendues concernant le transport des données.
De telles propriétés comprennent la fiabilité (réception de l’intégralité des données, exemptes d’erreurs), l’efficacité (la quantité des données émises maximise l’utilisation de la capacité du réseau) ou la résistance au facteur d’échelle.
Fiabilité
Des messages pouvant être perdus, reçus en erreur, en désordre ou dupliqués, des bits de contrôle sont inclus dans leur entête. Ces bits font référence à un numéro appelé numéro de séquence qui permet de détecter les messages manquants, de réordonner les messages ou de supprimer les doublons. On trouve également une somme de contrôle dont le rôle est de vérifier si le message contient des bits en erreur. Comme l’indique son nom, son calcul résulte de la somme des bits du message avant son envoi. A sa réception, le destinataire refait le même calcul et vérifie si le résultat coïncide avec la somme calculée par la source.
Efficacité
L’efficacité dans un réseau de données est similaire à celle qu’un transporteur met en œuvre pour s’assurer que ses fourguons sont tous utilisés au maximum de leur capacité de transport. L’efficacité peut également faire référence à la proportion du message occupée par son entête comparée à sa charge utile. Si envoyer un colis est facturé sur la base de son poids brut, l’expéditeur cherchera à minimiser le poids du carton d’emballage. Il en va du même des autoroutes dont le nombre de voies est déterminé de façon à éviter les bouchons mais également leur sous-utilisation. Le coût de réalisation et d’exploitation des autoroutes doit être en adéquation avec leur utilisation, leur financement dépendant des recettes aux péages. On parlera alors d’utilisation efficace des autoroutes. De la même manière, les coûts liés au déploiement et à la maintenance d’un réseau de données ainsi que sa capacité doivent être en adéquation avec le volume des données transportées, le nombre d’utilisateurs et le prix d’un abonnement Internet.
Résistance au facteur d’échelle
Une autre propriété est la résistance au facteur d’échelle (ou scalabilité). Il s’agit d’un principe de conception qui caractérise un système dont les performances ne sont pas, ou sont peu sensibles à une grandeur dénombrable croissante, caractérisant ce système. Cette grandeur peut faire référence au nombre d’utilisateurs ou de nœuds dans un réseau. Une autre grandeur peut aussi faire référence au nombre de messages en transit dans le réseau ou de requêtes que reçoit un serveur. Un transporteur de colis doit s’assurer du bon déroulement de ses opérations, y compris à l’occasion des fêtes de fin d’années.
Dans un réseau de données, pour assurer les nombreuses propriétés attendues concernant la livraison des données, un seul entête ne suffit pas.
Architecture en couches
Un message comprend donc une série d’entêtes ajoutée aux bits de données. Un entête est ajouté dans un but spécifique qui détermine le type d’informations contenues dans cet entête. L’ajout d’un entête se fait en sollicitant un programme qui prend en paramètre les bits de données.

Les bits de données passent par une série de programmes qui se relaient pour ajouter un entête supplémentaire avant que le message final soit prêt à être transmis sur le support de transmission. Le dernier programme à ajouter un entête, ajoute également des bits en fin du message appelés de ce fait enqueue du message.
A la réception du message final, les entêtes sont progressivement retirées en traversant une séquence de programmes similaire à celle traversée avant l’émission de ce message mais en sens inverse. Le dernier entête à avoir été ajouté est le plus externe (situé à gauche) et donc le plus accessible. Chaque programme accède uniquement à l’entête ajouté côté émetteur par son programme homologue.
Couches et protocoles
Dans Internet, les programmes qui contribuent à la préparation des données en vue de leur transmission sont au nombre de 5. En première position, on retrouve les programmes applicatifs qui génèrent les données côté émetteur et les consomment côté récepteur. En dernière position, on retrouve la carte réseau dont les composants matériels transforment le message sous la forme d’un signal émis sur le support de transmission.

Empilement. Par souci de représentation, ces programmes sont empilés les uns sur les autres et la traversée des données se fait de haut en bas côté émetteur et de bas en haut côté récepteur. On parle alors de couches en lieu et place des programmes, une même couche pouvant être implémentée de plusieurs manières différentes selon les propriétés attendues de cette couche.
Protocole. Une couche collabore avec sa couche homologue distante selon des règles bien précises concernant la structure de l’entête qu’elle ajoute et retire aux messages. Ces règles définissent également les actions à exécuter en vue de l’émission ou suite à la réception d’un message. De ces actions peuvent résulter l’installation, la mise à jour ou la suppression d’un état. Un état fait référence à une valeur stockée en mémoire qui caractérise l’état de l’échange entre deux machines. L’ensemble de ces règles forme un protocole. Pour communiquer entre elles, deux machines exécutent simultanément plusieurs protocoles, un par couche.
Standardisation. Certains protocoles ont été standardisés rendant ainsi leurs spécifications accessibles à tous. C’est le cas par exemple de HTTP, le protocole qui régit les communications entre navigateurs et serveurs Web. Les spécifications de HTTP étant publiques, plusieurs navigateurs sont proposés par différentes sociétés telles que Microsoft ou Google. Du fait d’avoir été développés conformément au standard, navigateurs et serveurs savent communiquer entre eux, le logiciel coté serveur étant également conforme au standard.
Entête de protocole. À la manière des étiquettes apposées sur un colis, un protocole ajoute un entête à l’émission d’un message. La position de cet entête est déterminée par la couche à laquelle le protocole appartient. L’entête est ajouté en vue d’être lu par sa couche homologue une fois le message reçu. Ce sont les informations de contrôle contenues dans les champs de cet entête qui permettent de déterminer les actions à entreprendre à la réception du message. Des exemples d’actions inclus l’installation ou la mise à jour d’un état, la génération d’une réponse sous la forme d’un message retourné à la source ou la suppression du message si reçu en erreur par exemple. De l’exécution de ces actions résultera le service attendu de cette couche.
Services de communication. Une même couche pouvant offrir différents types de service, certaines couches implement plusieurs protocoles. C’est le cas de la couche application qui implémente autant de protocoles que d’applications installées sur nos ordinateurs. Un service de communication résulte de l’exécution du protocole spécifique à la couche qui offre ce service.
L’ensemble des couches et des protocoles qu’elles implémentent constitue ce qui est communément appelée une architecture de réseau. Du fait de l’empilement des couches qui implémentent les protocoles, on parle aussi d’architecture en couches.
Internet et modèle OSI
Les composants logiciels et matériels qui permettent aux utilisateurs d’envoyer ou de recevoir des données via les applications qu’ils installent sur leur machine sont donc structurés en couches, au nombre de 5 dans Internet.
Les fonctions prises en charge par chacune de ses couches sont habituellement décrites en faisant référence au modèle OSI (Open Systems Interconnection) normalisé dans les années 1970 par l’ISO (International Organization for Standardization). Le modèle OSI comporte 7 couches identifiées par un numéro et un nom. La numérotation commence à 1 pour la couche la plus basse appelée couche Physique.

Sur les 7 couches du modèle OSI, seules 5 ont été implémentées dans Internet, les fonctions des couches numérotées 5 et 6, appelées Session et Présentation respectivement, étant prises en charge pour certaines par la couche 7. L’ensemble de ces couches et les protocoles qu’elles implémentent forment une architecture de réseau. On parle aussi de pile protocolaire pour faire référence à l’ensemble des protocoles réunis au sein d’une même architecture de réseau.
Couche Application (7)
L’architecture de Internet comprend au niveau le plus élevé la couche 7 appelée couche Application. Les programmes qui implémentent cette couche sont par exemple, les navigateurs Web côté client et les serveurs Web côté serveur. Leur but est d’exécuter le protocole HTTP (Hypertext transfer protocol) qui permet le téléchargement des pages Web.
Les deux couches suivantes nommées couche Transport (couche 4) et couche Réseau (couche 3) sont fournies avec les systèmes d’exploitation installés sur les ordinateurs personnels, les smartphones ou autres objets communicants.
Couche Transport (4)
La couche 4 appelée couche Transport offre deux services résultant de deux protocoles : TCP (Transmission control protocol) et UDP (User datagram protocol).
TCP segmente les données générées par l’application émettrice et ajoute à chaque segment un entête. Le message résultant de cette encapsulation est appelé segment. Dans le cas de UDP, les données générées par l’application ne sont pas segmentées. UDP se contente d’ajouter son entête aux données applicatives. Le message résultant de l‘encapsulation des données applicatives est appelé datagramme. Si la taille du datagramme le requiert, c’est la couche Réseau (3) sous-jacente qui se chargera de sa fragmentation.
C’est la couche Transport qui fournit aux développeurs l’interface de programmation, appelée socket, qui permet de concevoir des applications réseau.
Couche Réseau (3)
La couche 3 appelée couche Réseau implémente le protocole IP (Internet Protocol) qui ajoute à son tour un entête et le message qui en résulte est appelé paquet. Un paquet est donc un segment TCP ou un fragment de datagramme UDP auquel a été ajouté un entête de couche 3. Cet entête contient notamment les adresses source et destination du paquet. La couche 3 a pour rôle l’acheminement des paquets vers leur destination.
Couche Liaison de données (2)
La couche 2 appelée couche Liaison de données est à la fois logicielle et matérielle. La partie logicielle correspond aux pilotes qui permettent d’interagir avec la partie matérielle qui elle, correspond aux cartes réseau telles que Ethernet ou Wifi. La couche Liaison de données a la particularité d’ajouter un entête mais également un enqueue à la suite des bits de données du paquet pour former une trame.
Couche Physique (1)
La partie matérielle comprend également la couche 1 appelée couche Physique. Elle est responsable de la conversion des bits sous la forme d’un signal adapté aux supports de transmission. Dans l’architecture Internet, les couches 1 et 2 forment un tout dénommé interface réseau que l’on désigne usuellement par l’identifiant eth0 dans le cas des cartes Ethernet ou Wifi.
Les couches 1 et 2 dépendent des caractéristiques physiques du support de communication et du nombre de machines connectées à ce support.
Cœur vs. périphérie du réseau
Dans Internet, la pile TCP/IP fait référence aux deux protocoles implémentés respectivement par la couche Transport (4) et Réseau (3). Pour comprendre le rôle des couches 4 et 3 dans Internet, il est nécessaire de présenter les deux types de machines que l’on trouve dans les réseaux de données. Ces deux types de machines différent selon :
- leur position dans le réseau et
- les fonctions qui leur incombent.

Machines hôtes vs. routeurs
Machines hôtes. Le premier type de machines sont les ordinateurs personnels, tablettes, smartphones et autres dispositifs que nous utilisons pour accéder à Internet. Ces machines sont les seules où peuvent être installées et exécutées les applications dans un réseau. Du fait d’héberger les applications, ces machines sont appelées machines hôtes. Elles forment la périphérie du réseau où les données sont générées et consommées. Les machines hôtes sont donc situées aux extrémités des communications.
Routeurs. Le second type de machines sont les noeuds internes du réseau appelés routeurs. Ces derniers sont reliés entre eux par des liens selon une configuration formant un maillage partiel. Les routeurs et les liens les reliant forment ce qu’on appelle le cœur du réseau en opposition à la périphérie du réseau où se retrouvent les machines hôtes. Cette interconnexion de routeurs permet de minimiser le nombre de liens nécessaires pour connecter les machines hôtes entre elles.
Parmi l’ensemble des routeurs, on distingue ceux situés en bordure du cœur auxquels se connectent les machines hôtes pour accéder au réseau. Ces routeurs sont de ce fait dénommés routeurs d’accès. Les machines hôtes accèdent à Internet en contactant un premier routeur qui agit comme la passerelle par défaut appelée en anglais default gateway. Les machines hôtes qui utilisent les services d’une même passerelle sont connectées à un même réseau physique appelé réseau local.
Le rôle des routeurs découle de la topologie du réseau de cœur. Le maillage partiel entraîne l’existence de plusieurs chemins alternatifs entre paires de machines hôtes. Il est donc nécessaire pour chaque destination de sélectionner un chemin unique, le long duquel seront acheminés invariablement les messages tant que ce chemin reste disponible. Nous verrons que cette constance dans le choix du chemin emprunté par l’ensemble des messages pour une même destination est primordial pour la réparation efficace de leur perte.
Routage vs. acheminement
Le rôle d’un routeur est donc double. Le premier est l’acheminement des données, le second est le routage (ou sélection de chemins). Un routeur achemine les messages en les transmettant sur le lien de sortie qui les rapprochera de leur destination finale. Ce lien de sortie permet de joindre un nœud voisin appelé saut suivant. Le choix du saut suivant résulte d’un algorithme de routage dont l’objectif est de choisir un chemin pour chaque destination du réseau.

Algorithme de routage. Pour ce faire, certains algorithmes de routage calculent le chemin le plus court, la distance des chemins pouvant faire référence au nombre de routeurs qu’ils les constituent par exemple. C’est le cas de l’algorithme de Bellman-Ford. Si les liens sont configurés avec un coût, le chemin choisi est alors celui dont la somme des coûts des liens qui le constituent, est la plus petite. C’est le cas de l’algorithme de Dijkstra. D’autres algorithmes considèrent les accords commerciaux entre FAI (Fournisseurs d’accès Internet) qui collaborent pour acheminer les données sur des distances couvrant des zones géographiques étendues telles que des pays ou des continents.
Protocole de routage. Pour s’exécuter, ces algorithmes ont besoin de connaître la topologie partielle ou complète du réseau. Les routeurs la découvrent en exécutant un protocole de routage implémenté par la couche Réseau (3) des routeurs. Un protocole de routage permet aux routeurs de collaborer en échangeant des messages contenant des informations sur la topologie du réseau et selon les règles définies par le protocole de routage. Des exemples de protocole de routage sont RIP (Routing information protocol), OSPF (Open shortest path first) ou BGP (border gateway protocol).
Adressage. Pour calculer les chemins, les routeurs doivent connaître la position des nœuds au sein de la topologie du réseau. Pour ce faire, une valeur unique appelée adresse est attribuée à chacun des nœuds. Dans le cas de Internet, cette adresse est une valeur binaire longue de 32 bits appelée adresse IP. Les adresses IP sont présentées au format décimal pointé : les quatre octets qui les forment sont convertis en décimal et les valeurs décimales résultant de cette conversion séparées par un point.
A la manière des numéros de téléphone, les adresses IP sont attribuées hiérarchiquement par les fournisseurs Internet. Tout comme les indicatifs téléphoniques qui identifient une zone géographique, les premiers bits d’une adresse identifient le réseau auquel est connecté la machine à qui appartient l’adresse. Ces bits appelés préfixe réseau ont une longueur variable déterminée par le nombre de bits positionnés à 1 dans une adresse particulière appelée masque de réseau, défini pour tout réseau.
Nous verrons par la suite que les machines sont identifiées par une seconde adresse appelée adresse MAC, gérée par la couche Liaison de données.
Plan de données vs plan de contrôle. L’acheminement des données et la sélection des chemins qu’empruntent les données sont des fonctions réalisées par la couche Réseau (3). Les fonctions nécessaires à l’acheminement des données font partie du plan de données et celles nécessaires à la sélection des chemins font partie du plan de contrôle des routeurs.


Plan de gestion. En plus des plans de données et de contrôle, on trouve le plan de gestion qui réunit les fonctions nécessaires à la configuration et la supervision des plan de données et de contrôle des routeurs. C’est du plan de gestion que résulte par exemple la configuration du coût des liens nécessaire au protocole OSPF. Si les plans de données et de contrôle sont automatisés, le plan de gestion lui nécessite l’intervention manuelle d’un administrateur.
L’ensemble des autres fonctions nécessaires à la livraison des données sont prises en charge par les machines hôtes. Ces fonctions sont réalisées par la couche Transport, numérotée 4. Elles répondent aux besoins des applications qui s’exécutent au niveau 7. Ces fonctions incluent la fiabilisation des messages ou l’utilisation efficace et équitable de la bande passante du réseau.
Fiabilisation. Au cours de leur acheminement, des messages peuvent être perdus ou reçus en erreur. Dans l’architecture Internet, la correction des pertes de messages et des messages en erreur est à la charge de la couche Transport (4). Ces pertes pouvant résulter de l’absence de ressources nécessaires pour traiter les messages si en surnombre, il est nécessaire d’ajuster le débit d’émission des sources de façon à éviter les pertes qui pourraient s’ensuivre. Cet ajustement se fait équitablement parmi l’ensemble des sources dont les messages empruntent le même chemin. La bande passante utilisée par chacune de ces sources est répartie équitablement.
La couche Réseau (3) se retrouve sur l’ensemble des machines de l’Internet y compris les machines hôtes, ces dernières étant responsables de définir les adresses IP source et destination des paquets. La couche Transport (4), quant à elle, est présente uniquement sur les machines hôtes. Ce choix résulte d’un principe de conception appelé le principe du bout en bout.
Principe de bout en bout
Le principe de bout en bout exerce une force centrifuge sur les fonctions nécessaires à la livraison des données. Lorsque le choix est donné de concevoir une fonction en faisant intervenir, soit toutes les machines du réseau y compris les routeurs, ou uniquement les machines hôtes de la périphérie, il est recommandé de privilégier en priorité la seconde solution.
La logique du principe de bout en bout est d’éviter l’exécution répétée d’une même fonction sur l’ensemble des routeurs situés le long du chemin que traverse un message. Dans le cas de l’Internet, la longueur d’un chemin alterne en moyenne entre 15 et 20 sauts. En cantonnant l’installation d’une fonction uniquement aux extrémités, cette même fonction est exécutée deux fois. C’est le cas des fonctions nécessaires à la réparation d’un message en erreur ou perdu.
Fiabilisation de bout en bout
Dans Internet, la détection des messages en erreur résulte de l’utilisation d’une somme de contrôle qui permet au récepteur de détecter les messages contenant des bits de données en erreur. Ces erreurs peuvent intervenir plus en amont le long du chemin mais ce n’est qu’une fois le message acheminé jusqu’à sa destination finale qu’il sera rejeté par le récepteur qui prétendra ainsi ne pas l’avoir reçu.
L’absence d’accusé de réception provoquera l’expiration d’un temporisateur armé par la source à l’émission du message et la retransmission du message. La valeur du temporisateur de retransmission est calculée de façon à refléter la durée d’un aller-retour entre source et récepteur du message. Pour garantir la validité de cette valeur, il est nécessaire de préserver la longueur du chemin entre source et récepteur. De ce fait, l’acheminement des paquets dans Internet se fait le long d’un chemin unique qui ne changera qu’en cas de défaillance.
En limitant l’exécution de ces fonctions aux seules extrémités, on retarde la réparation d’un message en erreur. Ce retard est cependant acceptable en comparaison au délai et à la charge qu’aurait induit l’exécution d’une fonction similaire mais implémentée sur l’ensemble des routeurs du réseau.
Serveurs proxy
Il en va de même pour la plupart des fonctions nécessaires à la livraison des données. Cependant, des exceptions existent, notamment sous la forme des serveurs dits mandataires, appelés proxy servers en anglais. Un proxy est un équipement installé le long des chemins entre clients et serveurs. Leur rôle est d’intercepter les requêtes des clients et de se substituer, lorsque possible, aux serveurs. C’est le cas des caches Web qui stockent temporairement les pages Web les plus populaires afin d’accélérer leur livraison, les caches Web étant situés au plus prêt des clients comparés aux serveurs auxquels ils se substituent. Les caches Web assurent des fonctions applicatives censées être cantonnées à la périphérie du réseau. C’est dans ce sens que les proxys font exception au principe de bout en bout.
Mode datagramme vs mode circuit virtuel
Il existe d’autres architectures de réseau qui, contrairement à Internet, ont fait le choix d’impliquer les nœuds internes de leur réseau dans la fiabilisation des messages échangés. C’est le cas de Transpac par exemple dont les nœuds internes appelés commutateurs réservent préalablement les ressources nécessaires à l’acheminement des messages en vue d’éviter leurs pertes, faute de ressources. Ces ressources sont réservées au niveau des commutateurs situés le long du chemin qu’emprunteront par la suite les messages et ce, invariablement. L’ensemble des ressources réservées forme une connexion et le chemin, un circuit virtuel. On parle de service en mode circuit virtuel. Une rupture de lien ou la perte d’un des commutateurs situés le long d’un circuit virtuel entraîne l’interruption de la communication. Pour la rétablir, une nouvelle connexion est nécessaire.

Les mécanismes de réservation de ressources complexifient le fonctionnement des commutateurs et inexorablement, leur coût. Ce choix de conception n’a pas été suivi dans Internet. Le chemin n’étant pas fixé au préalable, on parle de service en mode datagramme. Un datagramme suit un chemin sans la garantie que les ressources nécessaires à son acheminement soient présentes. L’absence de ressources suffisantes fait référence à la congestion qui provoque la destruction des datagrammes en excès. Dans Internet, les datagrammes font référence aux paquets IP qu’on appelle aussi de ce fait, datagramme IP.
